04 : Blog
Grammario & YouTube
Published on: March 6, 2025
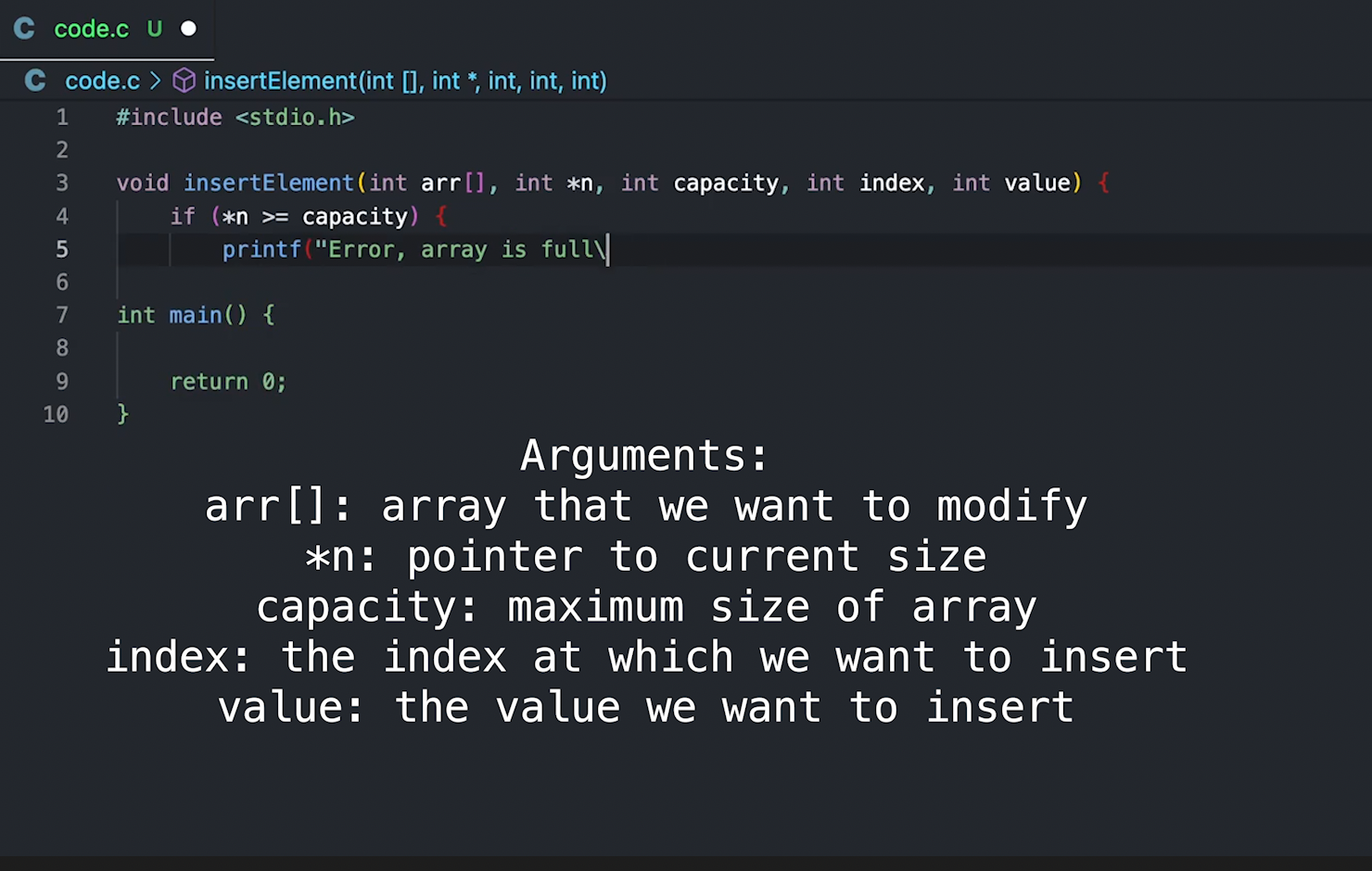
Due to certain hosting issues, I am unable to deploy the back end of Grammario which is responsible for the grammar breakdown. I am uncertain when this will be fixed as my job and work on Wheelbase take precedent.
On another note, I have decided to make some YouTube videos about the C programming language in my free time. I got this idea after watching some videos by a guy called Daniel Bourke, who has a PyTorch course up on YouTube. In one of his other videos, he claimed that trying to teach something will increase your knowledge in said subject. I believed him. Not knowing what to teach, I came to the idea that I should start from the basics, back to C. Where better to start? C teaches people about the guts of programming in the most intimate way possible that does not involve learning Assembly. Hopefully I will release my first video soon.
Grammario Update 1/1/25
Published on: January 1, 2025
And with the new year, I present version 0.1.0 of Grammario! It's very bare and is not polished whatsoever, but I do want to show the basic functionality to the world. Once that is tried and tested, then I will move to making the website world class!
Grammario Project Update 12/29/24
Published on: December 29, 2024
Utilizing some stuff I learned in the realm of prompt engineering, I was able to improve the prompt and we finally have an output that shows promises!
{
"sentence": {
"Ho": {
"position": 1,
"part_of_speech": "verb",
"root": "avere",
"noun_components": {
"affixes": null
},
"noun_case": null,
"noun_case_components": null,
"verb_tense": "present perfect",
"verb_tense_components": [
"ho"
]
},
"visto": {
"position": 2,
"part_of_speech": "verb",
"root": "vedere",
"noun_components": {
"affixes": null
},
"noun_case": null,
"noun_case_components": null,
"verb_tense": "past participle",
"verb_tense_components": [
"visto"
]
},
"una": {
"position": 3,
"part_of_speech": "article",
"root": null,
"noun_components": {
"affixes": null
},
"noun_case": null,
"noun_case_components": null,
"verb_tense": null,
"verb_tense_components": null
},
"bella": {
"position": 4,
"part_of_speech": "adjective",
"root": null,
"noun_components": {
"affixes": null
},
"noun_case": null,
"noun_case_components": null,
"verb_tense": null,
"verb_tense_components": null
},
"ragazza": {
"position": 5,
"part_of_speech": "noun",
"root": null,
"noun_components": {
"affixes": null
},
"noun_case": null,
"noun_case_components": null,
"verb_tense": null,
"verb_tense_components": null
}
},
"relationship_matrix": [
[
0,
0,
0,
0,
0
],
[
1,
0,
0,
0,
0
],
[
0,
0,
0,
1,
1
],
[
0,
0,
0,
0,
1
],
[
0,
0,
0,
0,
0
]
]
}
Grammario Project Update 12/21/24
Published on: December 21, 2024
In recent months other projects have taken priority over this passion project so I have unfortunately been taking a hiatus from this, but yesterday I finally drew up a rough outline of how I want this application to work.


Grammario Update 11/1/24
Published on: November 1, 2024
After the last update I have been playing around with prompt engineering in order to get the exact responses necessary to create the desired functionality, but as of right now it has proven fruitless. Sure, I could settle for inconsistent results that "kind of" work and get the basic ideas across but this is not what I want. However, this does not mean I am abandoning the idea of this project-far from it. I will continue to develop my machine learning skills and prompt engineering knowledge until I can create the functionality I so desire. Perhaps I shall even expand the project into a full language learning Web Application, instead of being exclusively to break down grammar. Since I have used every major language application that there is, whether it be Duolingo or LingQ etc.. I believe that I could create a structure that caters more to the enthusiast instead of someone who just keeps learning to keep their Duolingo streak going.
Grammario Update – September 19, 2024
Published on: September 19, 2024
In my recent work with Grammario, I’ve conducted several tests using the OpenAI API to break down grammar in Italian and Turkish, as well as testing with the Stanza library for Turkish grammar breakdowns with my own suffix-extraction logic.
Test 1: OpenAI API - Italian
The first test is a POST request using the OpenAI API to break down an Italian sentence.
{
"sentence": [
{
"part_of_speech": "verb",
"root": "avere",
"verb_tense": "present perfect",
"verb_tense_components": {
"auxiliary_verb": "ho",
"past_participle": "L'"
},
"word": "L'ho"
},
{
"part_of_speech": "verb",
"root": "fare",
"verb_tense": "past participle",
"verb_tense_components": {
"past_participle": "fatta"
},
"word": "fatta"
},
{
"part_of_speech": "verb",
"root": "imparare",
"verb_tense": "infinitive",
"word": "imparare"
},
{
"part_of_speech": "noun",
"root": "italiano",
"noun_components": {
"stem": "italian",
"suffixes": "o"
},
"word": "italiano"
}
]
}
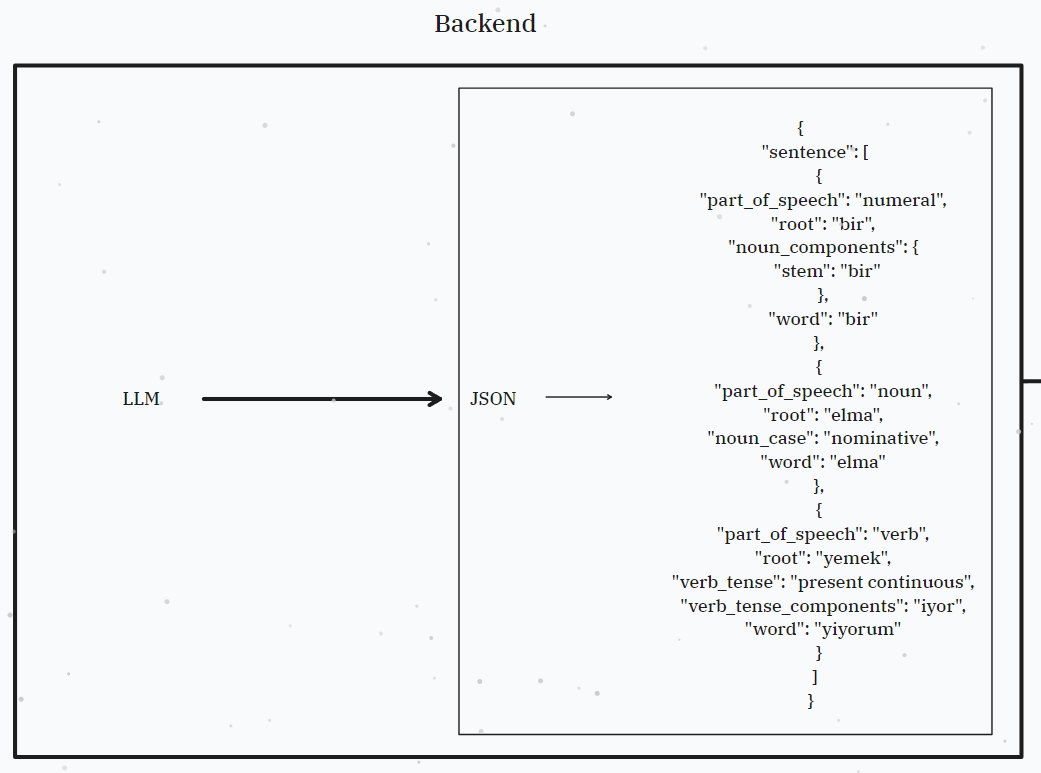
Test 2: OpenAI API - Turkish
The second test is a POST request using the OpenAI API to break down a Turkish sentence.
{
"sentence": [
{
"part_of_speech": "numeral",
"root": "bir",
"noun_components": {
"stem": "bir"
},
"word": "bir"
},
{
"part_of_speech": "noun",
"root": "elma",
"noun_case": "nominative",
"word": "elma"
},
{
"part_of_speech": "verb",
"root": "yemek",
"verb_tense": "present continuous",
"verb_tense_components": "iyor",
"word": "yiyorum"
}
]
}
Test 3: Stanza Library with Custom Suffix-Extracting Logic (Turkish)
The third test uses the Stanza library for Turkish grammar breakdowns, paired with my own logic for extracting suffixes.
Word: yapilan
Lemma: yap
Features: Aspect=Perf | Mood=Ind | Polarity=Pos | Tense=Pres | VerbForm=Part | Voice=Pass
Extracted Suffixes: ['-an', '-1l']
Word: seçimlere
Lemma: seçim
Features: Case=Dat | Number=Plur | Person=3
Extracted Suffixes: ['-e', '-ler']
Word: Reform
Lemma: reform
Features: Case=Nom | Number=Sing | Person=3
Extracted Suffixes: []
Word: Partisi
Lemma: parti
Features: Case=Nom | Number=Sing | Number[psor]=Sing | Person=3 | Person[psor]=3
Extracted Suffixes: ['-u']
Word: baskan
Lemma: baskan
Features: Case=Nom | Number=Sing | Person=3
Extracted Suffixes: []
Word: aday
Lemma: aday
Features: Case=Nom | Number=Sing | Number[psor]=Sing | Person=3 | Person[psor]=3
Extracted Suffixes: ['-u']
Word: olarak
Lemma: olarak
Features: None
Extracted Suffixes: []
Word: katildi
Lemma: kat
Features: Aspect=Perf | Mood=Ind | Number=Sing | Person=3 | Polarity=Pos | Tense=Past | Voice=Pass
Extracted Suffixes: ['-d1', '-1l']
These tests demonstrate how the different methods approach language grammar breakdowns. While OpenAI offers impressive results for both Italian and Turkish, I’ve found that the Stanza library combined with custom suffix-extracting logic offers more flexibility for specific language features like Turkish suffixes.
Moving forward, I’ll continue refining the custom logic to ensure accuracy and consistency in these breakdowns, with the ultimate goal of building a robust web application that simplifies grammar learning.
Grammario Project Background
Published on: September 17, 2024
A core hobby of mine is language learning. Throughout the years I have used many different websites, applications, and tools in order to make learning easier.
Language learning has always been a hobby of mine, but over time, I realized that mastering grammar can often be the most challenging aspect. After scouring the web for tools that could simplify this process, I found that many fell short of providing the depth and clarity needed. Leveraging my knowledge of natural language processing (NLP), I decided to introduce a web app that specifically tackles the complexities of grammar learning, aiming to make this daunting task easier for language learners like myself.
One of the key features of my web app is its ability to break down complex sentences, making grammar easier to understand. For instance, take the Italian sentence: "L'ho fatta parlare in italiano."
- L': A pronoun meaning "her," used as the direct object.
- ho: The verb "have," used as an auxiliary in the present tense.
- fatta: The past participle of "fare" (to make), agreeing with the feminine pronoun.
- parlare: The infinitive verb meaning "to speak."
- in: A preposition indicating the language.
- italiano: A noun meaning "Italian," referring to the language being spoken.
This breakdown simplifies understanding each part of the sentence, showing how the words connect and form the meaning. With this tool, learners can tackle even the most challenging grammatical structures step by step.